Apple apresenta avanço expressivo no desempenho de inteligência artificial local ao demonstrar o chip M5 superando o M4 em até quatro vezes no tempo para gerar o primeiro token de grandes modelos de linguagem (LLMs) executados diretamente no MacBook Pro por meio do framework MLX.

Quem está envolvido
A empresa responsável pelos testes e pelas novas medições de performance é a Apple. O anúncio parte da própria companhia, que detém o ecossistema de hardware e software utilizado nos experimentos: o chip M5, o notebook MacBook Pro e o framework de aprendizado de máquina MLX.
O que foi revelado
A principal revelação é a capacidade do M5 de reduzir drasticamente o Time to First Token (TTFT) — métrica que representa o intervalo entre o envio de uma solicitação a um modelo de linguagem e a entrega do primeiro caractere da resposta. O M5 atinge, nessas condições, uma velocidade até quatro vezes superior à vista no chip M4. Além disso, a geração contínua de tokens, etapa subsequente no processo de inferência, alcança ganho de 19 % a 27 % e, em casos específicos, chega aos 25 % de aceleração.
Quando e onde os testes ocorreram
Os dados foram divulgados nesta semana, tendo como ambiente de avaliação o MacBook Pro equipado com o novo processador. Toda a execução se deu localmente, sem dependência de servidores externos, característica que a Apple enfatiza como parte de sua estratégia de privacidade e eficiência energética.
Como o avanço foi obtido
Dois pontos estruturais explicam o salto de performance:
1. Novos Neural Accelerators
Unidades dedicadas a operações de multiplicação de matrizes foram incorporadas ao M5. Essas operações formam o núcleo computacional de redes neurais, e sua especialização possibilita manejar tensores de forma mais rápida e eficiente.
2. Aumento de largura de banda de memória
A taxa de transferência interna passou de 120 GB/s no M4 para 153 GB/s no M5. Como a geração contínua de tokens é limitada pela velocidade de acesso à memória, a expansão de banda remove gargalos e sustenta a aceleração observada.
Por que o resultado é importante
A redução no TTFT impacta diretamente a experiência do usuário e o fluxo de trabalho de desenvolvedores. Com respostas iniciais mais ágeis, sistemas de AI locais tornam-se mais responsivos, aproximando-se da fluidez normalmente associada a serviços executados em grandes data centers. A Apple destaca ainda os benefícios de segurança e privacidade derivados de manter os dados no próprio dispositivo.
Detalhamento do TTFT: quatro vezes mais rápido
Os testes conduzidos exibem quedas expressivas no TTFT para diferentes arquiteturas de modelos. Para o Qwen-1.7B, para o Qwen-8B e para o Qwen-14B — todos avaliados em múltiplas precisões — o intervalo inicial foi repetidamente inferior ao observado no M4. A mesma tendência se manteve nos modelos Mixture of Experts, entre eles Qwen-30B e GPT OSS-20B. Nessas arquiteturas, o M5 atingiu aceleração máxima de quatro vezes na entrega do primeiro token.
Geração subsequente: 19 % a 27 % de ganho sustentado
Passado o primeiro token, o modelo entra na fase de geração sequencial, quando novos tokens são produzidos até o texto final. Nessa etapa, o M5 registra vantagem que varia de 19 % a 27 %, resultado associado principalmente à largura de banda de memória superior. Em cenários específicos, os testes indicaram 25 % de melhoria, reforçando a consistência do ganho ao longo de toda a inferência.
A função dos Neural Accelerators
Multiplicações de matrizes sustentam o treinamento e a inferência de redes neurais. Ao introduzir aceleradores dedicados, o M5 processa tais operações sem sobrecarregar CPU ou GPU. A unidade especializada lida com altos volumes de cálculos paralelos, fator que contribui decisivamente para o corte no TTFT. A Apple associa o salto de velocidade principalmente a esse aprimoramento, complementado pela largura de banda aumentada.
Framework MLX: base dos testes
Lançado em 2023, o MLX opera como um framework aberto otimizado para chips Apple Silicon. Ele permite:
• Executar e treinar redes neurais localmente.
• Alternar processos entre CPU, GPU e Neural Engine sem mover dados, graças à arquitetura de memória unificada.
• Programar modelos com Python, Swift, C e C++, ampliando a acessibilidade a diferentes perfis de desenvolvedor.
Nos testes divulgados, o MLX foi o responsável por orquestrar a execução dos modelos e por obter as métricas comparativas entre M4 e M5.
Modelos avaliados
Foram considerados dois grupos de arquiteturas:
Modelos densos
• Qwen-1.7B
• Qwen-8B
• Qwen-14B
Modelos Mixture of Experts (MoE)
• Qwen-30B
• GPT OSS-20B
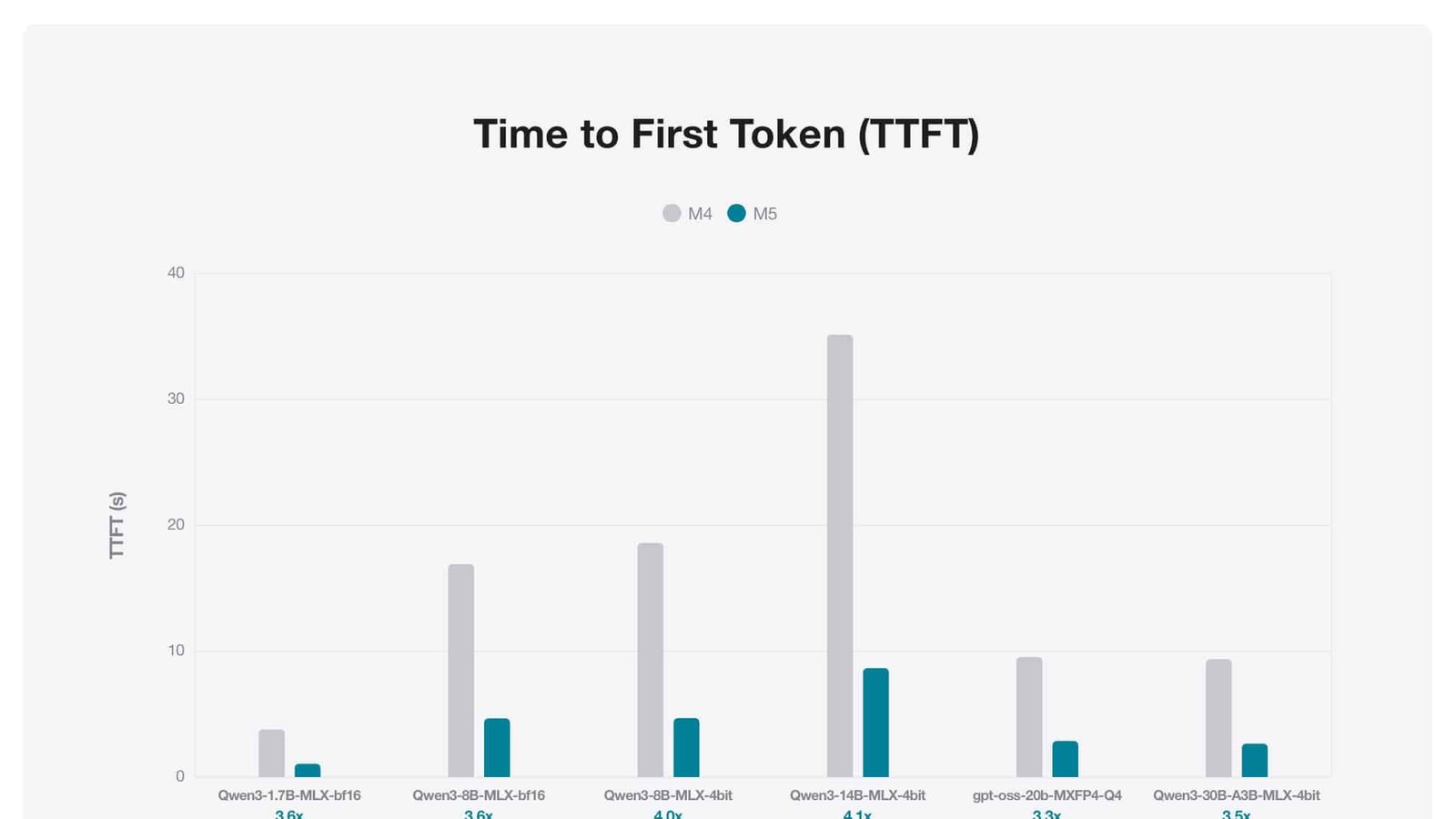
Imagem: Divulgação/Apple
A avaliação contemplou múltiplas precisões numéricas, incluindo versões quantizadas. A técnica de quantização de 4 bits permitiu que um MacBook Pro com 24 GB de memória unificada rodasse modelos de até 30 bilhões de parâmetros sem recorrer a recursos externos.
Resultados numéricos adicionais
• TTFT abaixo de 10 segundos para modelos densos de 14 bilhões de parâmetros.
• TTFT abaixo de 3 segundos para arquiteturas Mixture of Experts de 30 bilhões de parâmetros.
• Ganho contínuo de até 25 % na geração sequencial de tokens em relação ao M4.
Memória unificada: integrando CPU, GPU e Neural Engine
A arquitetura de memória unificada do Apple Silicon permite que diferentes unidades de processamento compartilhem o mesmo espaço de endereçamento. No M5, essa característica se torna ainda mais relevante porque:
• Evita cópias de dados entre componentes, reduzindo latência.
• Habilita o MLX a alternar tarefas de forma dinâmica, enviando cada operação para a unidade mais eficiente.
• Aproveita a largura de banda de 153 GB/s, que fornece throughput suficiente para alimentar os Neural Accelerators durante a geração contínua.
Comparação direta M4 x M5
Largura de banda
• M4: 120 GB/s
• M5: 153 GB/s
Tempo para o primeiro token
• Redução de até 4× no M5.
Geração subsequente de tokens
• Aceleração entre 19 % e 27 %, chegando a 25 % em determinados cenários.
Técnicas de quantização e uso de memória
A quantização de 4 bits reduz o tamanho dos parâmetros dos modelos, permitindo que arquiteturas mais robustas sejam executadas dentro do limite de 24 GB de memória unificada. Esse método, aplicado aos modelos de até 30 bilhões de parâmetros, mantém a inferência local e contida no hardware do usuário.
Estratégia focada em privacidade e eficiência
A Apple mantém uma postura consistente de valorizar a execução local de inteligência artificial como forma de proteger dados pessoais e economizar energia. O chip M5 reforça esse posicionamento ao viabilizar modelos complexos sem depender de nuvem, mostrando um caminho para pesquisadores e desenvolvedores testarem soluções completas em um ambiente totalmente local.
Impacto para desenvolvedores
Com o M5, quem trabalha com grandes modelos de linguagem pode:
• Avaliar protótipos de alto volume de parâmetros diretamente no MacBook Pro.
• Reduzir custo com infraestrutura externa, já que não há necessidade de instâncias na nuvem para testes iniciais.
• Iterar com mais rapidez, uma vez que o TTFT menor aumenta a agilidade no ciclo de desenvolvimento.
Implicações na experiência do usuário final
Usuários que dependem de assistentes baseados em linguagem ou aplicações que geram textos em tempo real se beneficiarão de:
• Respostas visíveis num intervalo de tempo significativamente menor.
• Menor dependência de conectividade: como o processamento ocorre no dispositivo, a latência de rede deixa de ser variável crítica.
• Preservação de dados: informações sensíveis permanecem no hardware local.
Perspectiva de continuidade
Ao disponibilizar os dados de desempenho no Apple Machine Learning Research, a Apple reforça o interesse em manter a comunidade informada sobre as melhorias de cada geração de chip. O M5, com seus aceleradores dedicados e largura de banda ampliada, estabelece um novo patamar de referência para inferência local em notebooks da companhia.
Com resultados que mostram TTFT de um dígito de segundos para modelos densos e de poucos segundos para arquiteturas Mixture of Experts ainda maiores, o M5 solidifica a ideia de que, no ecossistema Apple, grandes modelos de linguagem já podem ser tratados como recursos de borda, dispensando infraestrutura remota para uso cotidiano.

Paulistano apaixonado por tecnologia e videojogos desde criança.
Transformei essa paixão em análises críticas e narrativas envolventes que exploram cada universo virtual.
No blog CELULAR NA MÃO, partilho críticas, guias e curiosidades, celebrando a comunidade gamer e tudo o que torna o mundo dos jogos e tecnologia tão fascinante.

