Palavra-chave principal: IA para geração de interfaces

Visão geral do estudo
A Apple divulgou um estudo que propõe uma estratégia inédita para treinar modelos de inteligência artificial dedicados à criação de interfaces de usuário. A abordagem afasta-se do método tradicional de Aprendizagem por Reforço a partir do Feedback Humano (RLHF) e adota um sistema de recompensa alimentado por comentários, esboços e edições realizados por designers profissionais. O experimento reuniu 21 especialistas de diferentes níveis de experiência, que produziram 1.460 anotações convertidas em sinais numéricos para orientar o modelo escolhido, o Qwen2.5-Coder.
Quem participou
O grupo selecionado pela Apple foi composto por 21 designers. O documento menciona que esses participantes apresentavam níveis variados de domínio técnico, o que permitiu testar o método em um espectro amplo de perspectivas de design. Essa diversidade garantiu que o modelo de IA recebesse instruções, críticas e correções oriundas de profissionais seniores e também de perfis menos experientes, simulando situações de uso reais encontradas em equipes de desenvolvimento de produto.
O que foi testado
A experiência focou na geração automática de interfaces. O modelo base, Qwen2.5-Coder, recebeu dados estruturados de três formas: descrições em linguagem natural, capturas de tela anotadas e intervenções diretas sobre o protótipo de interface gerado. Cada uma dessas interações foi transformada em uma pontuação, que serviu como feedback quantitativo. O estudo ainda avaliou versões mais recentes do mesmo modelo para verificar se o mecanismo de recompensa se mantém eficiente quando aplicado em arquiteturas de IA diferentes.
Quando e onde a pesquisa se aplica
Embora o artigo não detalhe datas específicas de coleta, o experimento foi documentado no estudo “Improving User Interface Generation Models from Designer Feedback”. Por estar associado à Apple, o trabalho mira aplicações futuras em ambientes de desenvolvimento de software voltados a dispositivos da empresa e, potencialmente, a plataformas de terceiros. A pesquisa busca oferecer um caminho para acelerar projetos de interface sem depender exclusivamente de datasets estáticos, aproximando o processo de design humano ao ciclo de treinamento de IA.
Como o método difere do RLHF convencional
No sistema RLHF clássico, humanos avaliam saídas de IA e atribuem rótulos que indicam qualidade. Esses rótulos alimentam um algoritmo de reforço, direcionando ajustes de parâmetros. A Apple argumenta que esse fluxo não reflete a rotina de um designer, que raramente se limita a classificar versões estáticas com um “bom” ou “ruim”. Na prática, esses profissionais costumam rabiscar alternativas, reorganizar elementos visuais e registrar observações detalhadas.
O novo processo incorpora exatamente essas iniciativas. Ao permitir que o designer desenhe, mova componentes ou descreva o que deveria mudar, o modelo interpreta o gesto como informação estruturada. Em seguida, converte-o em um valor numérico que atua como a recompensa do algoritmo. Dessa forma, a IA ajusta suas futuras propostas de interface de acordo com correções concretas e contexto visual, não apenas segundo juízos binários.
Quantidade e tipos de anotações
Foram reunidas 1.460 anotações. Elas se dividiram em três categorias principais:
1. Comentários em linguagem natural: frases que descrevem problemas ou sugerem melhorias.
2. Capturas de tela com marcações: imagens nas quais o profissional circula áreas, adiciona setas ou destaca erros.
3. Edições práticas: mudanças diretas no layout — como mover botões, alterar cores ou reposicionar textos — feitas em protótipos gerados pela IA.
O estudo também testou a eficiência do processo com apenas 181 anotações. Mesmo com esse subconjunto menor, o modelo apresentou ganhos consideráveis, indicando que feedback especializado, ainda que reduzido, tem impacto expressivo na qualidade da interface obtida.
Métrica de recompensa
Cada anotação foi convertida em um escore numérico calibrado para que projetos de maior qualidade recebessem valores mais altos. Embora o estudo não revele a fórmula exata da pontuação, menciona que a calibragem priorizou resultados visualmente harmônicos, alinhamento correto de elementos e aderência às indicações textuais dos designers. Esse sistema direcionou o algoritmo a valorizar ajustes que se aproximassem de soluções profissionais, sem recorrer a métricas genéricas.
Comparação entre modelos
Três cenários foram analisados:
Modelo original: versões do Qwen2.5-Coder sem acesso às anotações de designers.
Modelo ajustado: Qwen2.5-Coder refinado com o novo mecanismo de recompensa.
Modelos externos: grandes LLMs proprietários, incluindo variáveis como o GPT-5, treinados apenas em bases de classificação ou avaliação tradicional.
Nas medições finais, o modelo ajustado superou tanto a versão original quanto os sistemas externos. O documento conclui que, para tarefas de geração de interface, um modelo relativamente menor, quando exposto a feedback especializado, pode igualar ou ultrapassar soluções mais robustas que não tiveram acesso ao mesmo tipo de dado.
Efeitos da quantidade de feedback
Com apenas 181 anotações, os ganhos já foram estatisticamente significativos. A equipe projeta que, se todas as 1.460 anotações fossem utilizadas, o desempenho poderia melhorar ainda mais. A hipótese baseia-se na tendência observada: cada ciclo adicional de reforço aproximou a IA do padrão almejado pelos designers, sugerindo que o sistema continua aprendendo de forma incremental sempre que novos comentários ou edições são incorporados.
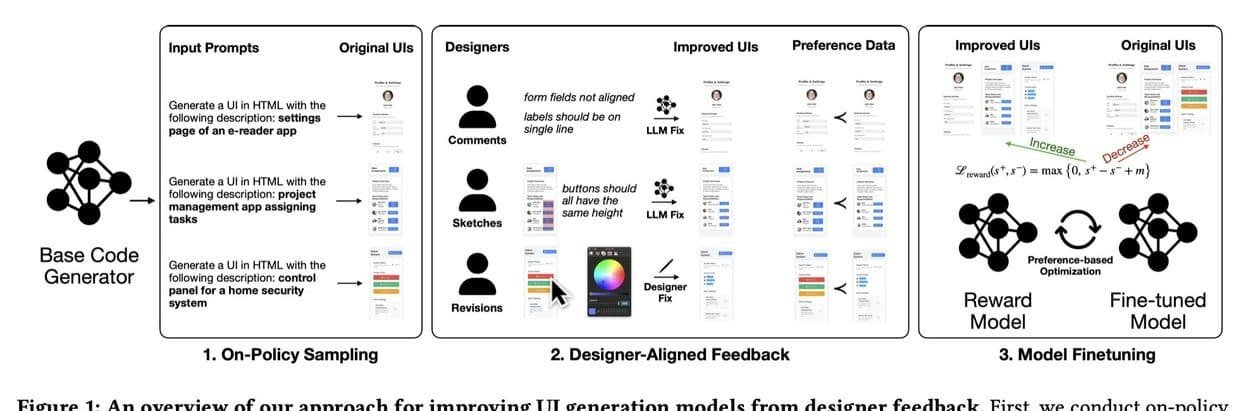
Imagem: Internet
Desafios na avaliação de qualidade
Durante o processo de validação, designers e pesquisadores precisavam escolher a melhor interface entre duas opções diferentes. Quando essa escolha dependia exclusivamente de julgamento visual, a concordância ficou em 49,2%, evidenciando a subjetividade envolvida em design. Ao mudar o formato de feedback para rascunhos sobrepostos, a taxa de concordância subiu para 63,6%. Com edições diretas na interface, o índice alcançou 76,1%.
Esses números indicam que, quanto mais tangível o feedback — passando de opinião abstrata para intervenção concreta —, mais fácil é alinhar percepções entre avaliadores distintos. Esse fenômeno reforça a justificativa da Apple para utilizar desenhos e modificações práticas como insumo principal do algoritmo de recompensa.
Causas para a estabilidade do novo método
O estudo atribui os resultados positivos a três fatores:
Enriquecimento semântico: comentários e esboços carregam contexto específico que vai além de rótulos simples.
Alinhamento com fluxo real de trabalho: designers não precisam mudar o modo como já colaboram entre si; a IA se adapta à rotina existente.
Calibragem contínua: por transformar cada correção em valor numérico, o ciclo de aprendizado permanece ativo, permitindo melhorias sem necessidade de recomeçar o treinamento.
Consequências para a indústria
Embora o documento se concentre na área de design de interface, o modelo proposto pode interessar a equipes de desenvolvimento de software, empresas de prototipagem e plataformas que automatizam UX. A capacidade de extrair aprendizados de um conjunto relativamente pequeno de feedback especializado pode reduzir custos e acelerar prazos de projeto, principalmente em equipes que já contam com profissionais empenhados em revisar layouts.
Limitações identificadas
Entre os obstáculos reconhecidos, destacam-se:
Subjetividade: mesmo com esboços e edições, o acordo entre avaliadores não atinge 100%, mostrando que preferências pessoais continuam influenciando decisões.
Escopo da amostra: apenas 21 designers participaram. Embora haja diversidade de experiência, o número pode não refletir toda a pluralidade de estilos existente no mercado global.
Dependência de ferramentas específicas: o fluxo exigiu capturas de tela e protótipos em formatos compatíveis com o sistema usado no experimento; mudanças de plataforma podem demandar ajustes no pipeline de anotação.
Próximos passos sugeridos pela pesquisa
O documento menciona a intenção de ampliar o conjunto de anotações, incluir mais versões de modelos e testar escalonamento do método em contextos diferentes de interface, possivelmente abrangendo fluxos de aplicativos móveis, software desktop e experiências web. A proposta também prevê análise de como o mecanismo de recompensa se comporta quando combinado a datasets convencionais de classificação, procurando encontrar um equilíbrio entre quantidade e qualidade de dados.
Impacto potencial sobre modelos proprietários maiores
Ao demonstrar que um modelo de porte médio, reforçado por comentários qualificados, pode superar sistemas maiores treinados em bases genéricas, o estudo sugere que a vantagem competitiva de gigantes da IA não depende apenas do volume de parâmetros ou de dados. A qualidade e a especialização do feedback aparecem como variáveis decisivas. Esse resultado pode incentivar outras empresas a investir em ciclos curtos de interação com especialistas de domínio, em vez de depender exclusivamente de megadatasets públicos.
Considerações sobre adoção corporativa
Para organizações que desejam implementar a metodologia, dois elementos serão fundamentais:
Planejamento de coleta de feedback: definir ferramentas para capturar esboços, comentários e edições de forma padronizada.
Integração no pipeline de treinamento: criar rotinas automáticas capazes de transformar anotações em recompensas numéricas sem intervenção manual constante.
A Apple demonstra que, ao estruturar esses pontos, é possível receber contribuições de uma equipe de design durante o próprio processo de criação de produtos, reduzindo fricção entre etapas de ideação, prototipagem e codificação.
Conclusão informativa
O estudo da Apple expõe evidências de que feedback prático, fornecido por designers por meio de comentários, capturas anotadas e edições diretas, aprimora significativamente a capacidade de um modelo de inteligência artificial gerar interfaces de usuário. Com 21 profissionais, 1.460 anotações e um sistema de recompensa calibrado, o método elevou a qualidade das propostas de layout, ultrapassando tanto a versão original do modelo quanto LLMs maiores que não receberam esse tipo de orientação especializada. A pesquisa destaca a eficiência de pequenos volumes de feedback qualificado e abre caminho para novas formas de colaboração entre IA e profissionais de design.

Paulistano apaixonado por tecnologia e videojogos desde criança.
Transformei essa paixão em análises críticas e narrativas envolventes que exploram cada universo virtual.
No blog CELULAR NA MÃO, partilho críticas, guias e curiosidades, celebrando a comunidade gamer e tudo o que torna o mundo dos jogos e tecnologia tão fascinante.

